適學(xué)人群
-

擁有多年從業(yè)經(jīng)驗的大數據從業(yè)者
渴望突破自我職業(yè)瓶頸,轉型推薦系統工作 -

具有數學(xué)學(xué)習背景的高校畢業(yè)生
希望可以從實(shí)際項目中理解推薦系統
提升工作經(jīng)驗
擁有多年從業(yè)經(jīng)驗的大數據從業(yè)者
渴望突破自我職業(yè)瓶頸,轉型推薦系統工作
具有數學(xué)學(xué)習背景的高校畢業(yè)生
希望可以從實(shí)際項目中理解推薦系統
提升工作經(jīng)驗
系統性梳理整合大數據技術(shù)知識與機器學(xué)習相關(guān)知識
深入了解推薦系統在電商企業(yè)中的實(shí)際應用
深入學(xué)習并掌握多種推薦算法
基于統計的離線(xiàn)推薦基于隱語(yǔ)義模型的離線(xiàn)推薦基于自定義模型的實(shí)時(shí)推薦基于Item-CF的離線(xiàn)相似推薦
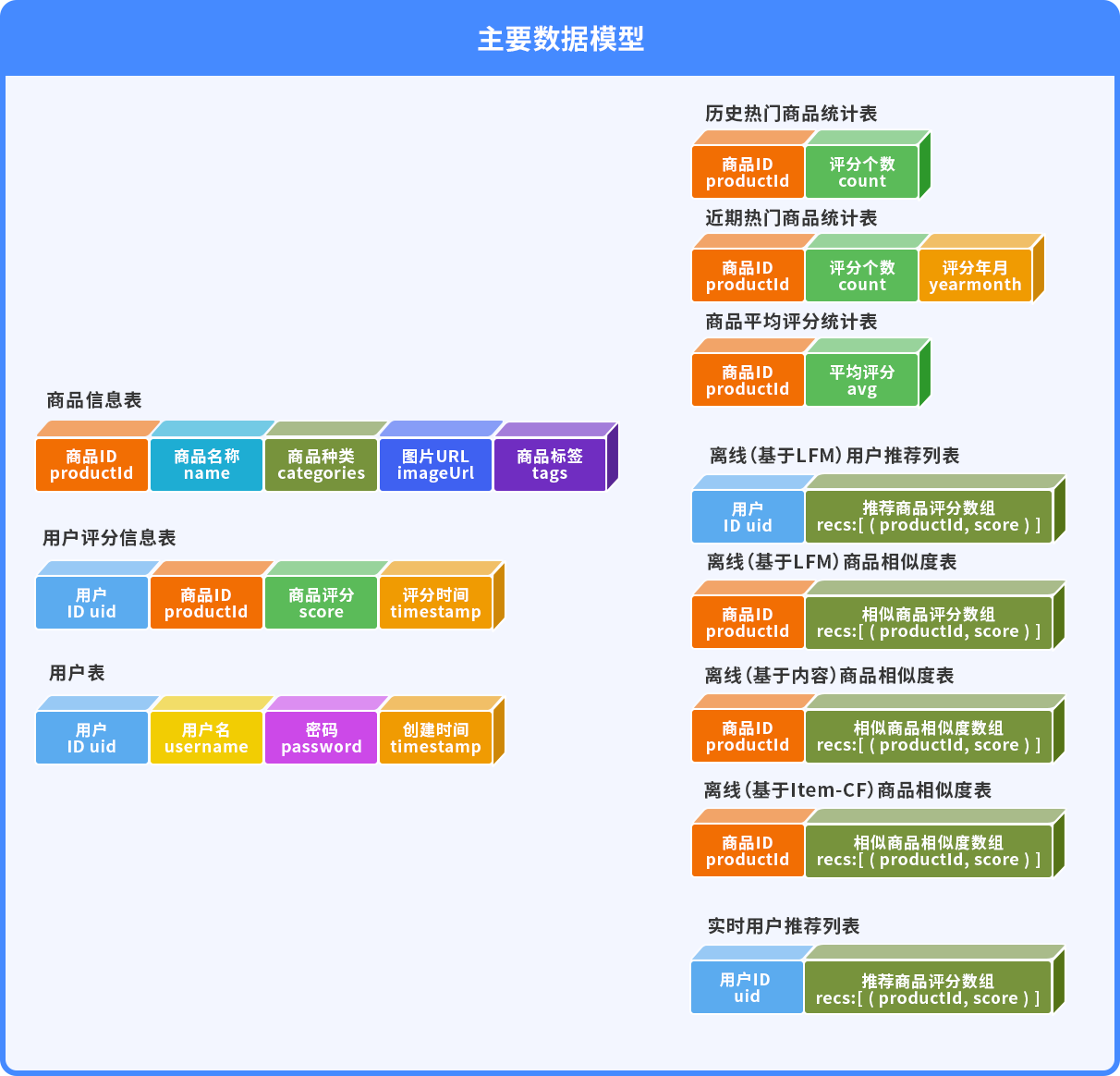

使用Flume、Kafka搭建實(shí)時(shí)數據采集系統,對多樣化的用戶(hù)行為數據和大體量的業(yè)務(wù)數據進(jìn)行采集清洗和系統調優(yōu);

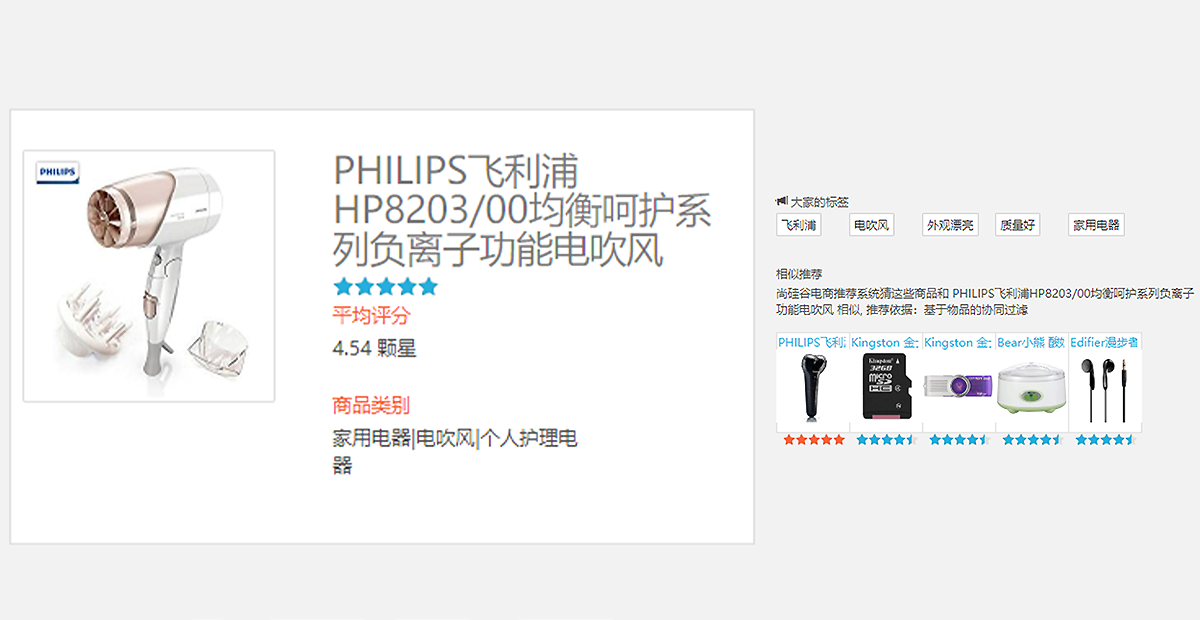
使用ALS算法對評分矩陣做矩陣分解,根據商品的隱語(yǔ)義特征計算商品之間的相似度,并將相似度做倒排索引,并將倒排數據持久化到MongoDB;

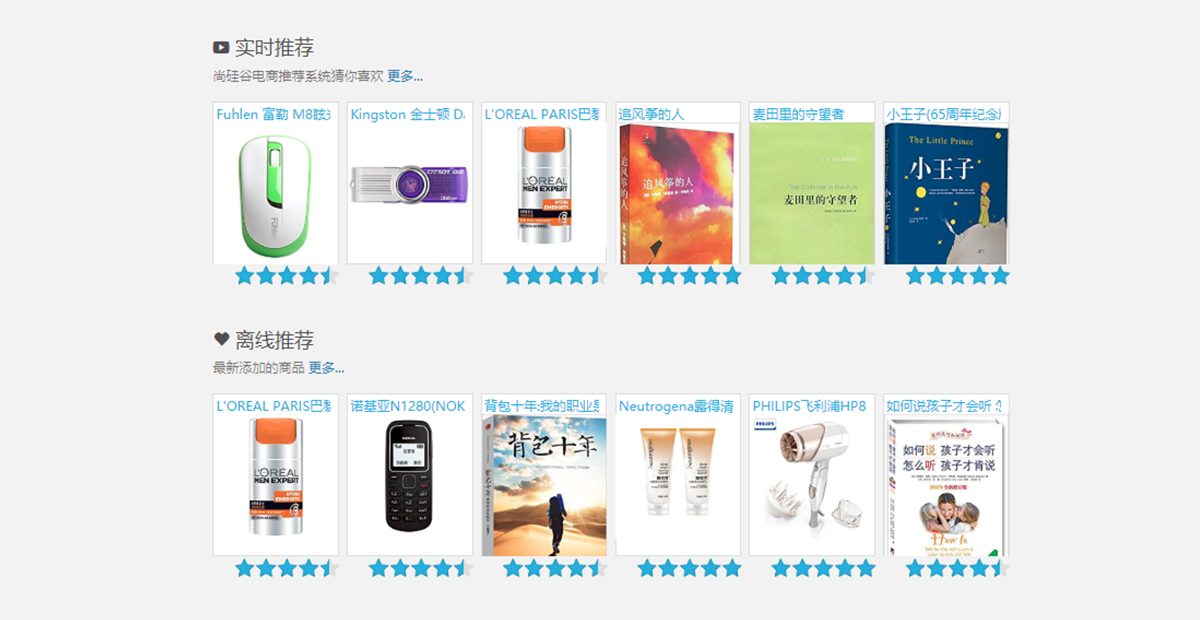
實(shí)時(shí)推薦:利用商品的相似度倒排,根據用戶(hù)商品評分或者點(diǎn)擊行為來(lái)做推薦,使用Spark Streaming來(lái)實(shí)時(shí)計算推薦優(yōu)先級,然后存儲到Redis中,提高用戶(hù)的訪(fǎng)問(wèn)體驗;

利用商品的標簽數據,使用TF/IDF來(lái)計算商品之間的相似度,同樣使用倒排的思路持久化道MongoDB;

使用Spark計算每個(gè)門(mén)類(lèi)的平均評分商品來(lái)解決冷啟動(dòng)問(wèn)題;

使用Spark將日志數據做分析和處理,然后持久化到MongoDB、ES等數據庫中,實(shí)現data loader功能;

通過(guò)A/B測試來(lái)評估推薦結果;

優(yōu)化Spark的計算效率,比如將一些數據進(jìn)行.cache()操作緩存,對某些數據做broadcast廣播到其他節點(diǎn),加快運算;

使用Git進(jìn)行版本管理,遠程代碼倉庫使用自己搭建的gitlab;

將推薦系統引擎模塊化:als矩陣分解的相似度計算、基于tfidf的相似度計算、實(shí)時(shí)推薦模塊,每一個(gè)引擎都會(huì )產(chǎn)生一個(gè)推薦列表,對不同的引擎賦予不同的權重,然后合并列表,產(chǎn)生推薦數據。

地址:北京市昌平區宏福科技園2號樓3層(北京基地)
深圳市寶安區西部硅谷大廈B座A區一層(深圳基地)
上海市松江區谷陽(yáng)北路166號大江商廈4層(上海基地)
武漢市東湖高新區天頤科技園C棟3層(武漢基地)
西安市雁塔區和發(fā)智能大廈B座3層(西安基地)
成都市成華區北辰星拱青創(chuàng )園綜合樓2層(成都基地)
